Cloudera CDP.In practice.At scale.
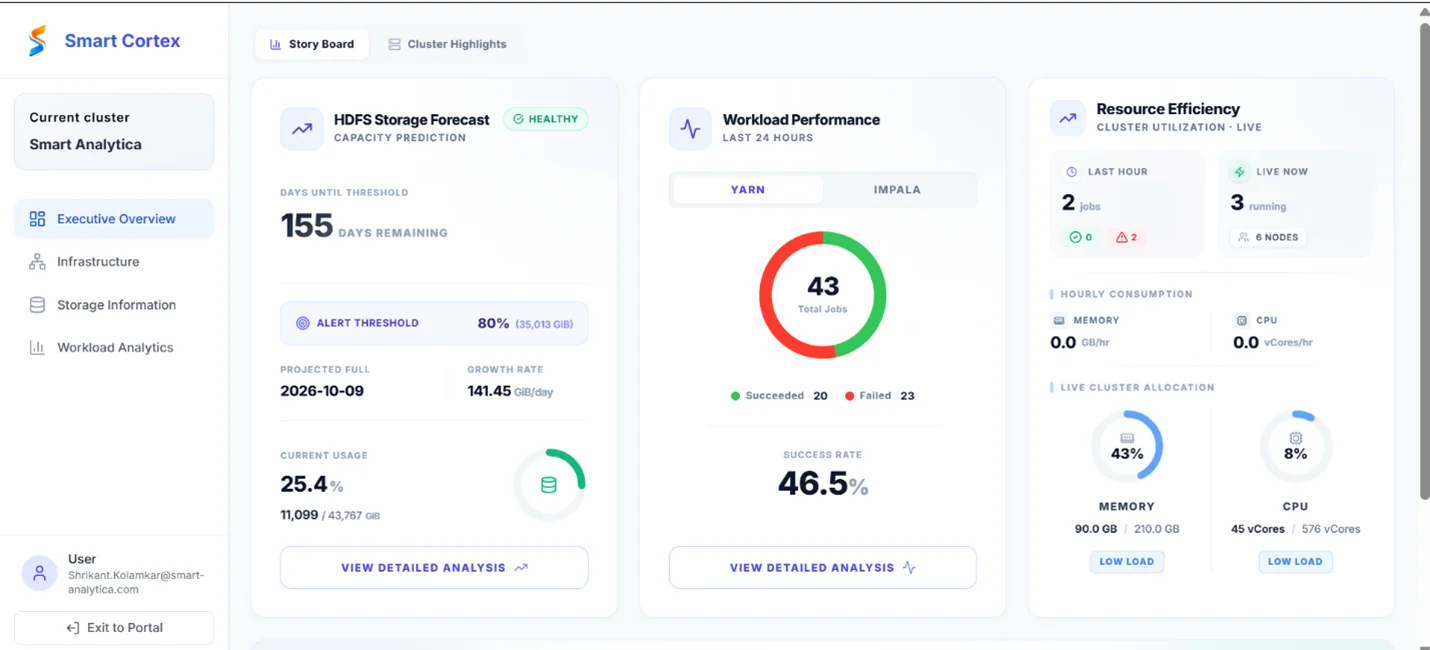
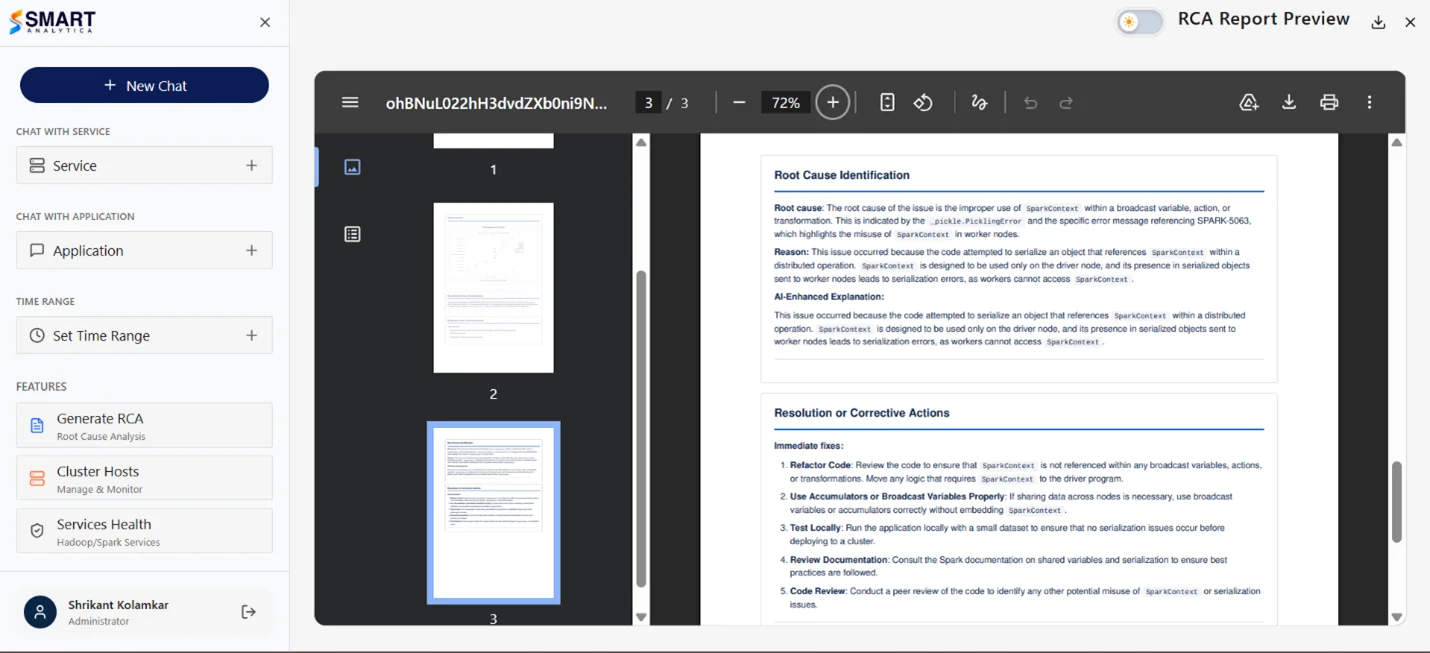
We engineer Cloudera CDP end to end, net-new builds, migrations off non-Cloudera platforms, and live estates that need to go further with AI on top. 100+ PB engineered on Cloudera. Modernize, harden, activate, we do all three.
100+ PB
Engineered on Cloudera
1M+/s
Streaming peak